Whisper, el nou model de reconeixement i transcripció de la parla de l'equip de OpenAI és un model totalment lliure i el van publicar el 21 de setembre de 2022
És un model de ASR (Automatic Speech Recognition) entrenat amb 680,000 hores de diferents àudios en múltiples llenguatges i múltiples accents. D'aquesta manera, Whisper amb una arquitectura de transformers és capaç de detectar l'idioma en el qual qualsevol persona parla i passar aquest àudio a text en la mateixa llengua o completament traduït en una altra.
A més, Whisper, com molts altres models, compta amb diferents versions per al seu ús. Aquestes versions canvien en la quantitat de paràmetres que tenen i, per descomptat, el pes de cada model en grandària és afectat per la quantitat de paràmetres amb els quals va ser entrenat, de manera que a més paràmetres mes pes el model i mes recursos requereix.
Models i idiomes disponibles
Hi ha cinc grandàries de models, quatre amb versions només en anglès, que ofereixen avantatges i desavantatges de velocitat i precisió. A continuació es mostren els noms dels models disponibles i els seus requisits aproximats de memòria i velocitat relativa.
| Tamany | Paràmetres | Model només en anglés | Model multilingüe | VRAM requerida | Velocitat relativa |
|---|---|---|---|---|---|
| diminut | 39 milions | tiny.en |
tiny |
~1GB | ~32x |
| base | 74 milions | base.en |
base |
~1GB | ~16x |
| petit | 244 milions | small.en |
small |
~2 GB | ~6x |
| mijà | 769 milions | medium.en |
medium |
~5GB | ~2x |
| gran | 1550 M | N / A | large |
~10GB | 1x |
Com funciona Whisper per a l'espanyol i català?
La resposta és, aparentment molt bé, els següents són els resultats amb el model més robust, en el qual mesuren el WER (word error rate) que mesura el rendiment en la sortida del text i la referència del script.
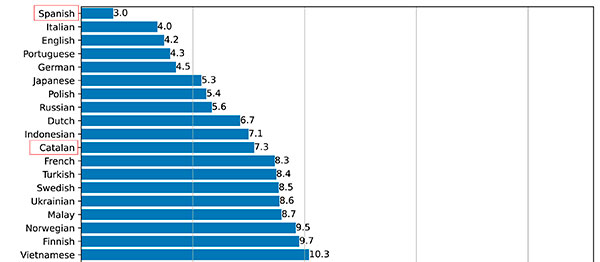
Recursos Whisper