SORA - OpenAI

Prompt: A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.
Sora és un model d'intel·ligència artificial desenvolupat per OpenAI capaç de generar vídeos realistes i imaginatius a partir d'instruccions textuals. Aquest model pot crear vídeos de fins a un minut de durada mantenint una alta qualitat visual i adherència a les indicacions de l'usuari. A més, OpenAI està explorant la capacitat de Sora per a entendre i simular el món físic en moviment, amb l'objectiu de resoldre problemes que requereixen interacció en el món real.
Sora és capaç de generar escenes complexes amb múltiples personatges, tipus específics de moviment i detalls precisos del subjecte i el fons. El model comprèn no sols el que l'usuari ha demanat en el missatge, sinó també com existeixen aquestes coses en el món físic.
El model té un profund coneixement del llenguatge, la qual cosa li permet interpretar indicacions amb precisió i generar personatges convincents que expressen emocions vibrants. Sora també pot crear múltiples preses dins d'un sol vídeo generat que persisteixen amb precisió els personatges i l'estil visual.
El model actual té febleses. És possible que tingui dificultats per a simular amb precisió la física d'una escena complexa i és possible que no comprengui casos específics de causa i efecte.
El model també pot confondre els detalls espacials d'un missatge, per exemple, barrejant esquerra i dreta, i pot tenir dificultats amb descripcions precises d'esdeveniments que tenen lloc al llarg del temps, com seguir una trajectòria de càmara específica.
NERF - LUMA AI

Només amb 5 imatges d'entrada, obtenim aquest resultat.
NERF és un acrònim que significa Neural Radiance Fields. És una tècnica d'intel·ligència artificial que s'utilitza per a crear objectes i entorns tridimensionals en temps real. NERF utilitza un model de xarxa neuronal per a generar un camp de radiació que representa la forma i la il·luminació dels objectes en un escenari virtual.
El model NERF s'entrena amb dades d'escenes 3D realistes, i després pot generar escenes noves a partir d'una descripció de l'escena desitjada.
Això permet als desenvolupadors crear objectes i entorns d'alta qualitat amb una velocitat i flexibilitat molt majors que amb tècniques tradicionals de modelatge 3D.
A més, el model NERF és capaç de fer tasques avançades, com la interacció amb objectes i la simulació de la llum i l'ombra, la qual cosa ho fa ideal per a aplicacions en videojocs, animació i realitat virtual.
La tècnica NERF és única en el sentit que utilitza un enfocament basat en camps per a representar els objectes i la llum en una escena 3D. Els camps són funcions matemàtiques que descriuen la forma i la il·luminació dels objectes en un escenari virtual.
RUNWAY
Les eines de Runway es divideixen en dues categories.
La primera (primer vídeo) és una versió millorada de les eines d'edició tradicionals però ajudades per intel·ligència artificial. El més destacat és que, amb un sol clic,inclou alguns efectes molt espectaculars i fàcils d'aplicar, entre ells el croma verd (green screen) i l'eliminació d'objectes (impainting) que en altres editors requereixen mòduls o un complicat procés d'edició al detall.
La segona (segon vídeo), a més de la creació d'imatges a partir d'un prompt (no oblidem que són els coautors de Stable Diffusion), és la recent creació de Gen-1.
Gen-1 es tracta d'una potent i eficient aplicació capaç de modificar vídeos i pel·lícules ja creades i transformar-les en uns altres completament nous valent-se únicament d'entrades de text.
Runway revela que el seu sistema de IA de generació de vídeo accepta l'entrada de text i imatge per a crear nou contingut de vídeo utilitzant videoclips existents.
Diverses companyies van llançar models de text a vídeo en 2022. Meta va presentar Make-a-Vídeo i Google Phenaki i Muse. Totes dues solucions admeten la creació de videoclips curts utilitzant l'entrada de text d'un usuari. Google va llançar Dreamix, recentment, que sembla ser la més similar de les tecnologies en comparació amb Gen-1. Igual que la solució de Runway, Dreamix utilitza contingut de vídeo existent i li aplica nous estils.
SYNTHESIA
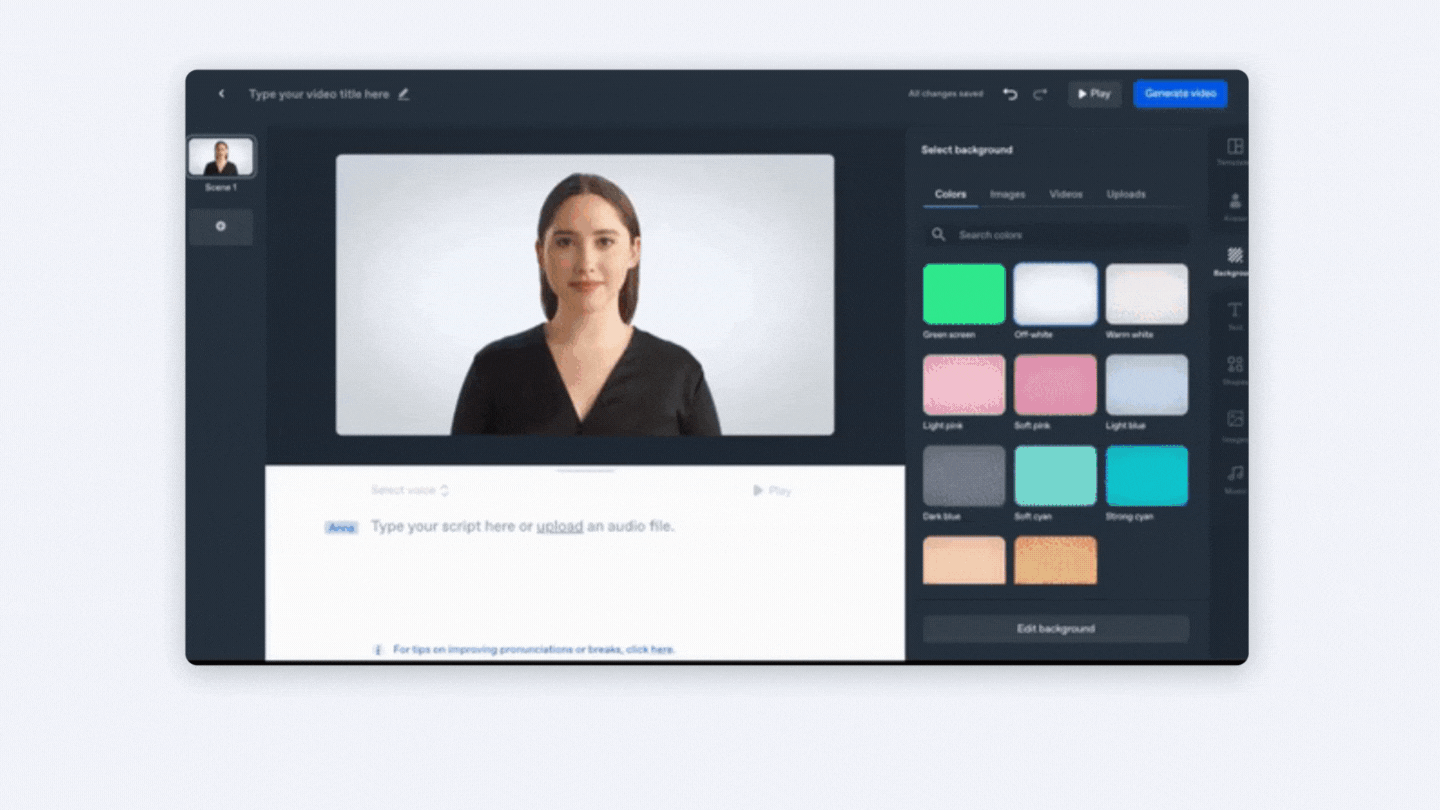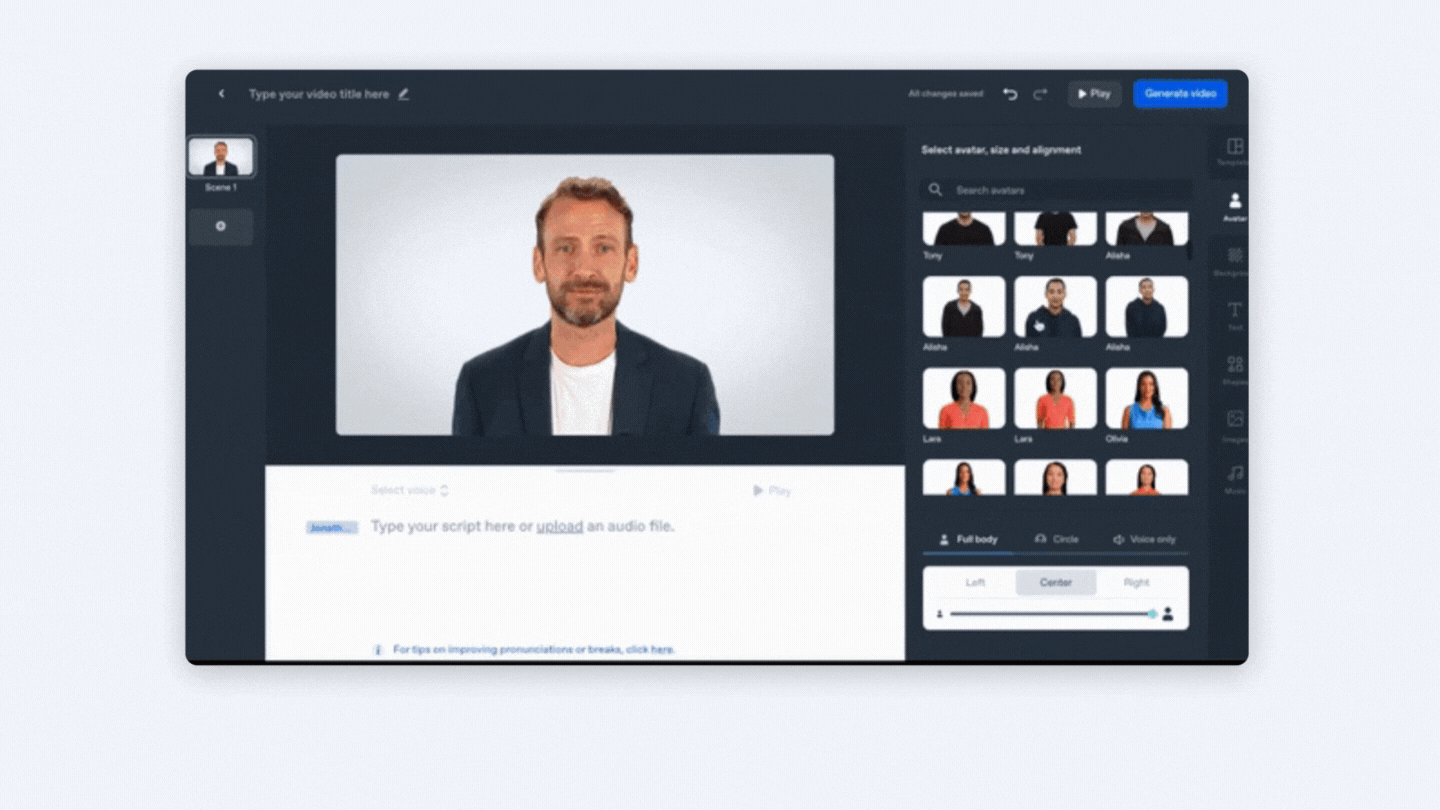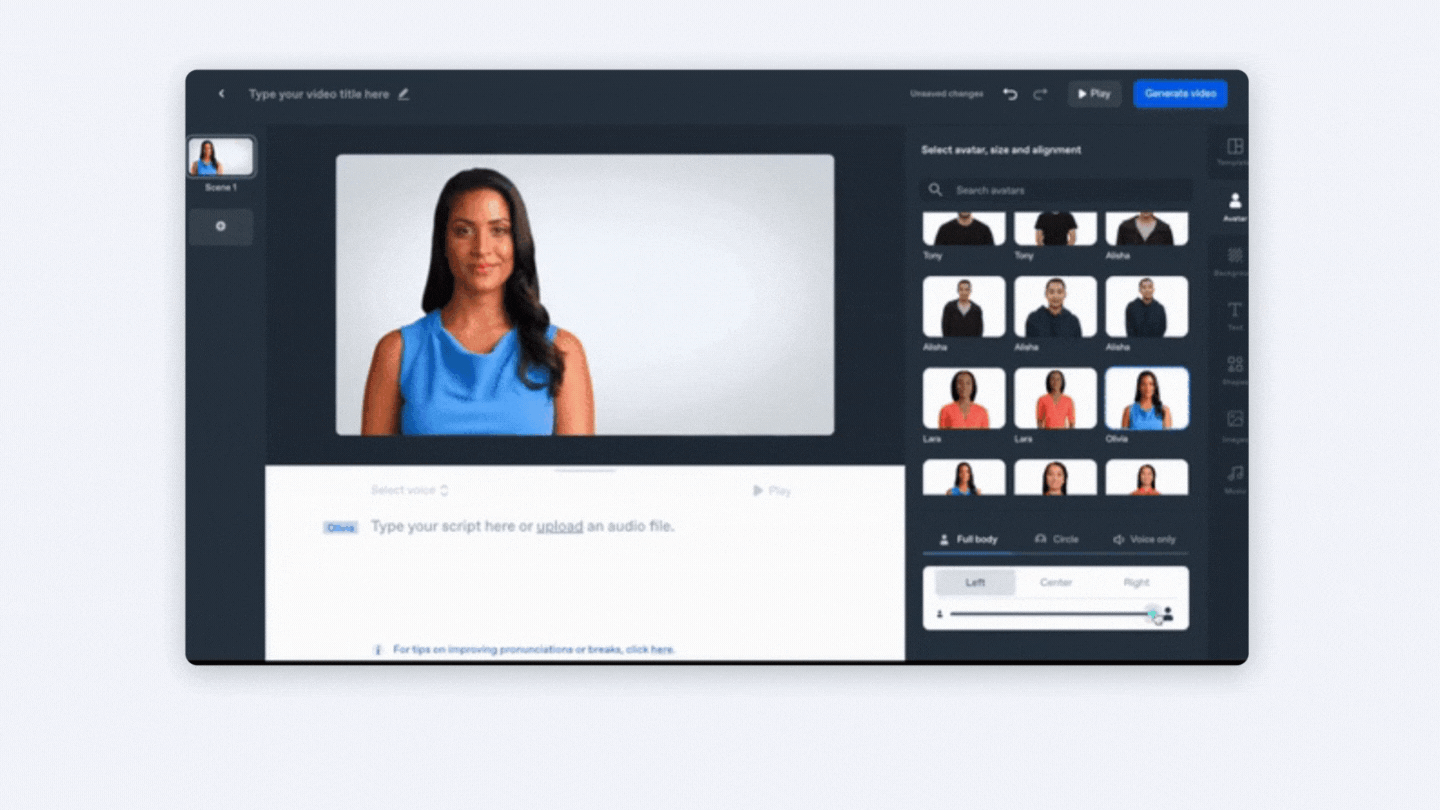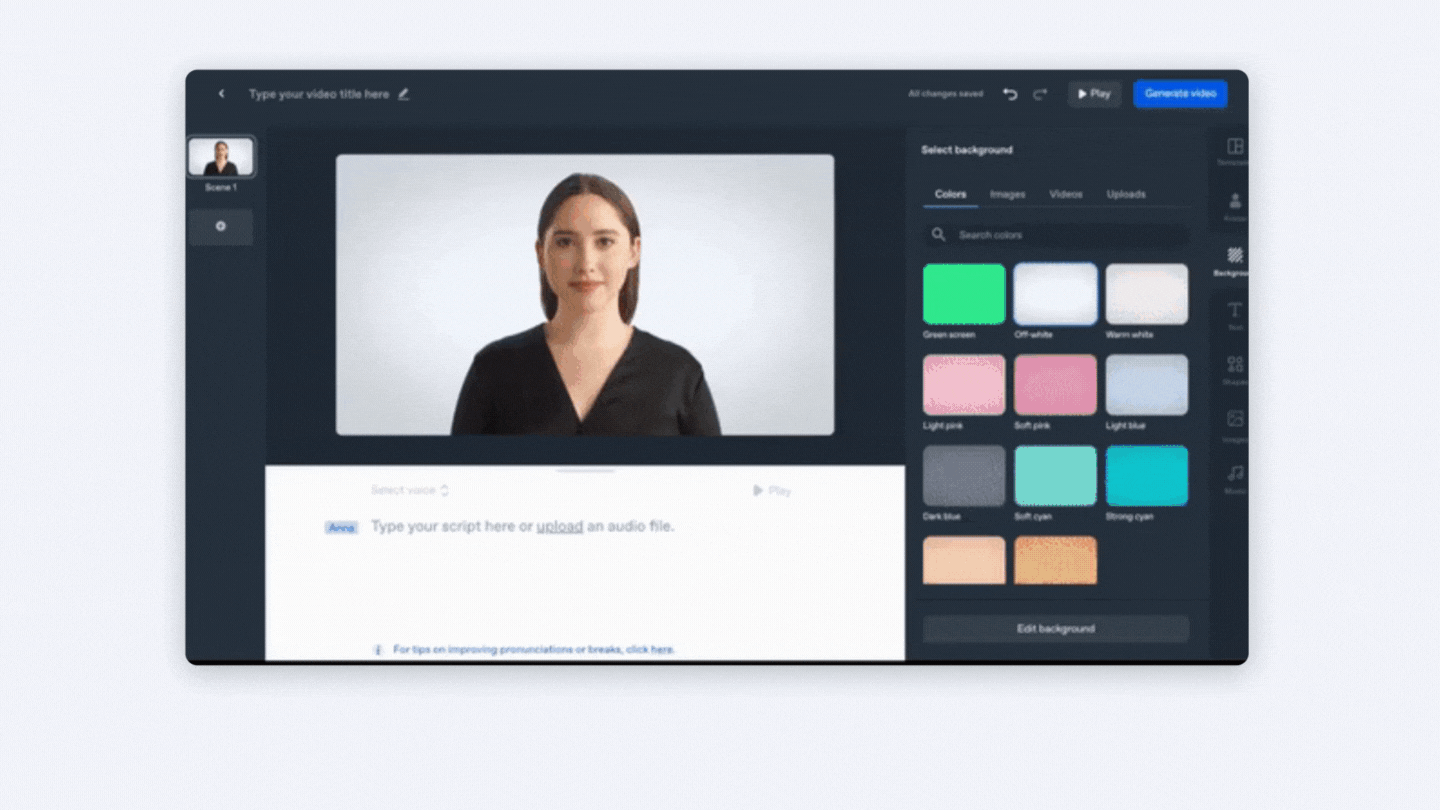
Aplicació Synthesia.
Synthesia és una plataforma que et permet crear ràpidament vídeos amb avatars de IA, en més de 120 idiomes. Inclou plantilles, una gravadora de pantalla, una biblioteca multimèdia i més.
Pots utilitzar actors professionals o avatars personalitzats, ja no és necessari preocupar-se per equips de vídeo costosos i trobar un lloc de filmació, utilitza un avatar de IA per a actuar com a presentador en el teu vídeo, disposes d'accés a plantilles totalment personalitzables i també pots editar i actualitzar el teu vídeo en qualsevol moment.
Pensat per crear vídeos explicatius de productes explicant ràpidament el valor del seu producte o servei, compartir resultats clau amb vídeos breus en lloc d'articles extensos o mantenint actualitzats als clients amb butlletins ràpids en vídeo o simplement fer petits videotutorials per ensenyar qualsevol cosa.