ChatGPT va commocionar el món amb la seva capacitat per a conversar de manera natural. No obstant això, ChatGPT no pot veure. És possible un model que pugui llegir una imatge i conversar amb un usuari?
Els models de llenguatge gran tamany (LLM) han guanyat molta força recentment, amb molts models populars que apareixen com GPT (Open-AI i Microsoft), OPT i LLaMA (Meta), Bard (Google) , BLOOM (Open source) i més. Aquests models sobresurten en l'aprenentatge del llenguatge natural, la qual cosa els fa perfectes per a crear chatbots, assistents de codificació, assistents per a la presa de decisions o sistemes de traducció. No obstant això, manquen de coneixement quan es tracta d'altres modalitats; per exemple, no poden processar imatges, àudio o vídeo. Aquí és on entra BLIP, per a millorar les capacitats de llenguatge natural de LLM amb comprensió visual.
Tanmateix, els propers models que estan preparant, tant Microsoft (GPT4) i Google (PaLM-E ), ja anuncien que seran multimodals, per tant, ho podran fer.
D'una banda, hi ha preguntes que no poden respondre's només amb text o només amb imatges, per la qual cosa necessitem un model que pugui combinar els dos mons. Per exemple, tasques com el subtitulat d'imatges, la resposta a preguntes visuals i moltes més.
A més, en els últims mesos l'atenció d'experts i premsa s'ha centrat en ChatGPT, un chatbot que pot respondre de manera natural a una infinitat de preguntes i és capaç de programar, escriure poesia i moltes altres coses. D'altra banda, ChatGPT és bàsicament un LLM al qual s'ha aplicat l'aprenentatge per reforç, i un enfocament similar pot aplicar-se a qualsevol LLM
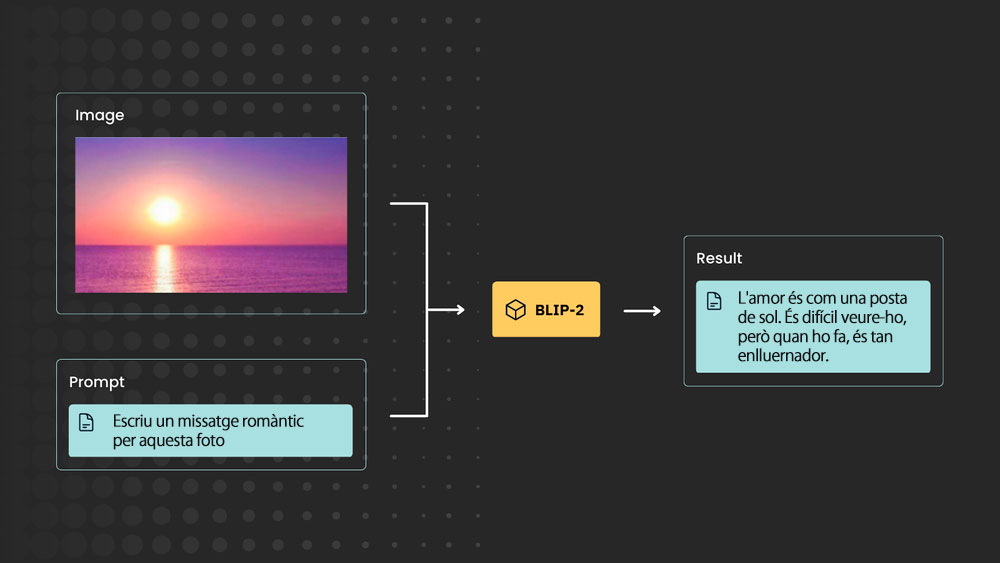
Així doncs, necessitem un model que sigui capaç de respondre a preguntes tant sobre imatges com sobre text (model visual) i que tal vegada pot respondre a preguntes com ChatGPT, no diguem més: BLIP-2 és el que necessites i el millor és que els punts de control són aquí en HuggingFace (Open Source).
Per què és important el BLIP-2?
BLIP-2 aprofita eficaçment tant els models d'imatge preentrenats congelats com els models lingüístics. I ho fa utilitzant un nou component lleuger i eficient, el Q-former. Això permet a BLIP-2 aconseguir un rendiment capdavanter en diverses tasques de visió i llenguatge.
Utilitzant models LLMs (com FlanT5 i OPT (Meta)), BLIP2 pot aprofitar la generació d'imatge a text "que segueix instruccions de llenguatge natural, la qual cosa permet capacitats emergents com el raonament de coneixement visual, la conversa visual, etc.".
Exemples:

